
现在的IT行业并不像以前那么好混了,从业人员过多,导致初级程序员过剩,这也间接导致了公司的招聘门槛越来越高,要求程序员掌握的知识也越来越多。
算法也是一个争论了很久的话题,程序员到底该不该掌握算法?不同的人有不同的答案,而事实上,很多公司都对算法有一定的要求,有些公司直接在面试的时候便会要求面试者手写算法题。这就对程序员的技术要求产生了很大的考验,所以面对如今的大环境,我们必须掌握算法,才能在今后的工作中占据一席之地。
那么接下来,我就简单介绍一下几个排序算法,希望对你们有所帮助。
1.冒泡排序
冒泡排序(Bubble Sort),是一种较简单的排序算法。
它重复地走访过要排序的元素列,依次比较两个相邻的元素,如果他们的顺序(如从大到小、首字母从A到Z)错误就把他们交换过来。走访元素的工作是重复地进行直到没有相邻元素需要交换,也就是说该元素列已经排序完成。
这个算法的名字由来是因为越大的元素会经由交换慢慢“浮”到数列的顶端(升序或降序排列),就如同碳酸饮料中二氧化碳的气泡最终会上浮到顶端一样,故名“冒泡排序”。
演示:
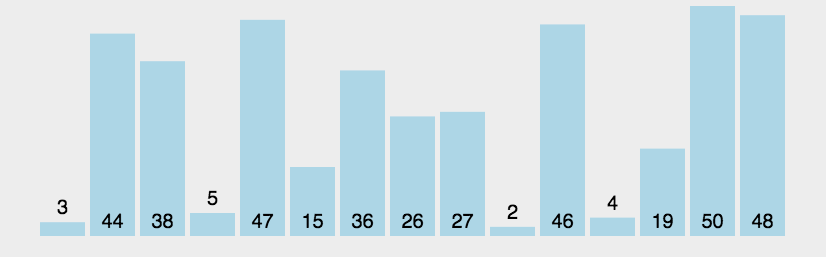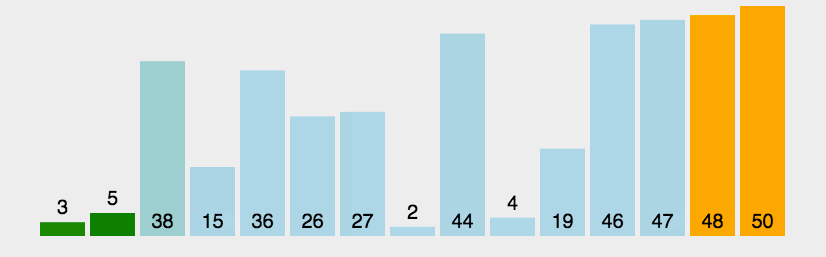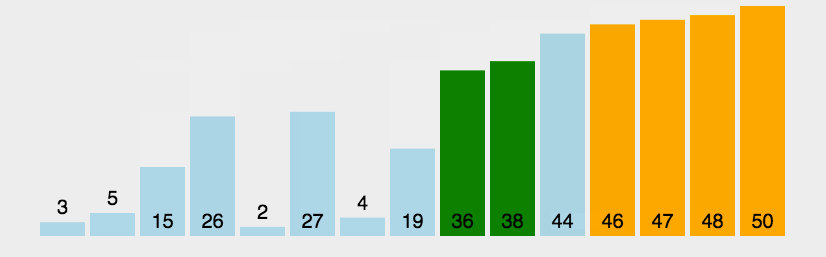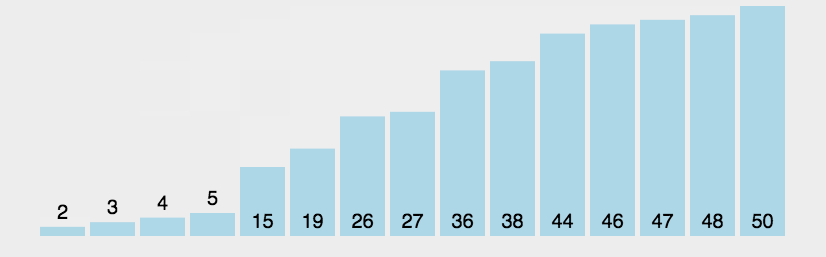
代码如下:
@Test
public void bubbleSort() {
int[] arr = { 3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48 };
// 统计比较次数
int count = 0;
// 第一轮比较
for (int i = 0; i < arr.length - 1; i++) {
// 第二轮比较
for (int j = 0; j < arr.length - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
// 交换位置
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
count++;
}
}
System.out.println(Arrays.toString(arr));
System.out.println("一共比较了:" + count + "次");
}运行结果:
[2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50]
一共比较了:105次
这段代码相信大家都能够写出来,一般冒泡排序也就是这样写。但是这段程序有个缺点,就是当排序过程中已经将数组元素排序完成,但此时它仍然会去比较,这就做了无用功了,所以我们可以通过一个boolean变量来优化这段代,上面的程序中我们已经得出了比较次数为105次。
优化代码:
@Test
public void bubbleSort() {
int[] arr = { 3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48 };
// 统计比较次数
int count = 0;
for (int i = 0; i < arr.length - 1; i++) { boolean flag = true; for (int j = 0; j < arr.length - 1 - i; j++) { if (arr[j] > arr[j + 1]) {
// 交换位置
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
flag = false;
}
count++;
}
if(flag) {
break;
}
}
System.out.println(Arrays.toString(arr));
System.out.println("一共比较了:" + count + "次");
}
运行结果:
[2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50]
一共比较了:95次
我们首先在开始循环时定义了一个boolean变量为true,然后如果元素之间进行了交换,就将值置为false。所以,我们就可以通过这个boolean变量来判断是否有元素进行了交换。如果boolean变量为true,则证明没有元素进行交换,那么久说明此时的数组元素已经完成排序,那么跳出外层循环即可,否则就继续排序。通过结果也可以看出,比较次数确实是减少了很多。
2.选择排序
选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理是:第一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后再从剩余的未排序元素中寻找到最小(大)元素,然后放到已排序的序列的末尾。以此类推,直到全部待排序的数据元素的个数为零。选择排序是不稳定的排序方法。
演示:
@Test
public void SelectionSort() {
int[] arr = { 3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48 };
for (int i = 0; i < arr.length - 1; i++) {
int index = i;
for (int j = 1 + i; j < arr.length; j++) {
if (arr[j] < arr[index]) {
index = j;// 保存最小元素的下标
}
}
// 此时已经找到最小元素的下标
// 将最小元素与前面的元素交换
int temp = arr[index];
arr[index] = arr[i];
arr[i] = temp;
}
System.out.println(Arrays.toString(arr));
}运行结果:
[2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50]
实现也非常的简单,首先在外循环里定义了一个index变量存储i的值,这是为了避免重复地比较,因为在每一轮的比较结束后,前i个元素是已经排好序的,所以无需再次比较,只需从i开始即可。后面的比较都是基于index位置的元素进行比较,倘若比较完后index位置的元素是最小值,那就无需交换,不动即可。而如果找到了比index位置的元素更小的元素,那就将该元素的索引赋值给index,然后继续比较,直到比较完成,比较完成之后得到的index即为数组中的最小值,那此时只需要将index位置的元素和i位置的元素交换即可。
3.插入排序
插入排序(Insertion sort)是一种简单直观且稳定的排序算法。如果有一个已经有序的数据序列,要求在这个已经排好的数据序列中插入一个数,但要求插入后此数据序列仍然有序,这个时候就要用到一种新的排序方法——插入排序法,插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得到一个新的、个数加一的有序数据,算法适用于少量数据的排序,时间复杂度为O(n^2)。是稳定的排序方法。插入算法把要排序的数组分成两部分:第一部分包含了这个数组的所有元素,但将最后一个元素除外(让数组多一个空间才有插入的位置),而第二部分就只包含这一个元素(即待插入元素)。在第一部分排序完成后,再将这个最后元素插入到已排好序的第一部分中。
插入排序的基本思想是:每步将一个待排序的记录,按其关键码值的大小插入到前面已经排序的数组中的适当位置上,直到全部插入完为止。
演示:
代码如下:
@Test
public void InsertionSort() {
int[] arr = { 3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48 };
for (int i = 1; i < arr.length; i++) { // 定义待插入的数 int insertValue = arr[i]; // 找到待插入数的前一个数的下标 int insertIndex = i - 1; while (insertIndex >= 0 && insertValue < arr[insertIndex]) {
arr[insertIndex + 1] = arr[insertIndex];
insertIndex--;
}
arr[insertIndex + 1] = insertValue;
}
System.out.println(Arrays.toString(arr));
}
运行结果:
[2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50]
那么在这里,因为数组元素我们并不确定,所以只能将数组的第一个元素看成是一个有序的序列,所以从数组的第二个元素开始才是我们需要去寻找插入位置的元素。所以外层循环从1开始,然后将arr[i],也就是当前的第二个元素先保存起来,然后找到待插入元素的前一个元素下标,也就是i-1,此时通过一个while循环去比较。
当insertIndex小于0时应该退出循环,因为此时已经与前面的所有元素比较完毕。在比较的过程中,如果待插入元素小于前一个元素,就将前一个元素后移,也就是将前一个元素的值直接赋值给待插入元素位置。因为在最开始已经将待插入元素进行了保存,所以只需将待插入元素的值赋值给它的前一个元素即可。因为在while循环中insertIndex执行了自减操作,所以它的前一个元素下标应为insertIndex + 1。而如果待插入的元素值大于前一个元素,那么就不会进入while循环,这样insertIndex + 1之后的位置仍然是自己所在的位置,所以赋值后值不改变,后面的操作以此类推。
4.希尔排序
传统的插入排序算法在某些场景中存在着一些问题,例如[2,3,4,5,1]这样的一个数组,当我们对其进行插入排序的时候,发现要插入的数字是1,而要想将1插入到最前面,需要经过四个步骤,分别将5、4、3、2后移。所以得出结论:如果较小的数是我们需要进行插入的数,那效率就会比较低。鉴于这种场景的缺陷,希尔排序诞生了,它是插入排序的一种更高效的版本。
先看看希尔排序的概念:
希尔排序(Shell’s Sort)是插入排序的一种又称“缩小增量排序”(Diminishing Increment Sort),是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。该方法因D.L.Shell于1959年提出而得名。
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
演示:

动画如果没有看懂,我这里再贴几张静态图:
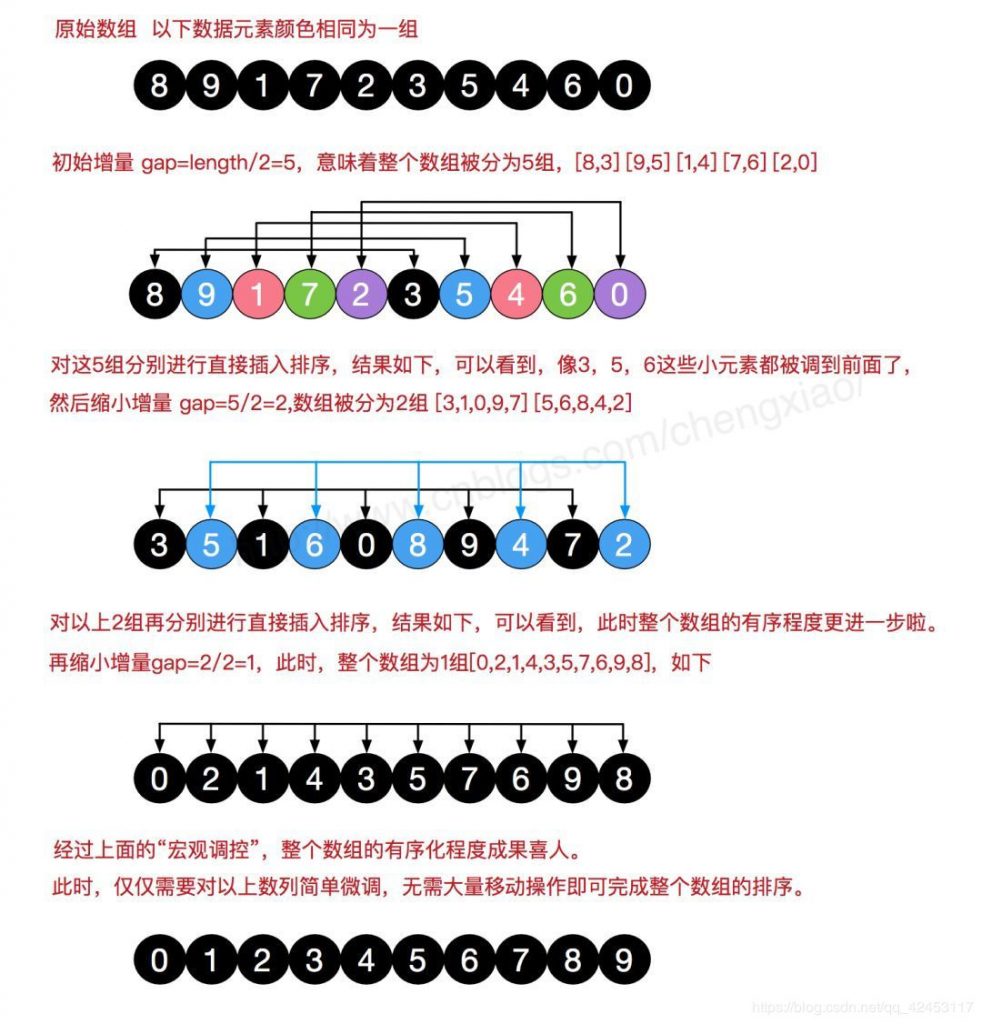
代码实现:
@Test
public void ShellSort() {
int[] arr = { 3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48 };
for (int gap = arr.length / 2; gap > 0; gap /= 2) {
// 对数组元素进行分组
for (int i = gap; i < arr.length; i++) {
// 遍历各组中的元素
for (int j = i - gap; j >= 0; j -= gap) {
// 交换元素
if (arr[j] > arr[j + gap]) {
int temp = arr[j];
arr[j] = arr[j + gap];
arr[j + gap] = temp;
}
}
}
}
System.out.println(Arrays.toString(arr));}
运行结果:
[2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50]
那么在上面的程序段中,数组长度为15,所以在第一轮,数组被分为了15 / 2 = 7个小组,然后分别对每个小组的元素进行遍历。在第一轮中小组之间的元素间隔都为7,所以分成的小组数其实也就是元素之间的间隔。接着就可以对每个小组的元素进行比较,然后进行交换,接下来以此类推。
————————————————
原文链接:https://blog.csdn.net/qq_42453117/article/details/99680831