
1.1 数据库基础
1.1.1 什么是数据库(DataBase)
数据库是一个以某种有组织的方式存储的数据集合,也就是:保存有组织的数据的容器(通常是一个文件或者一组文件)。
对于数据库的介绍有很多术语,也可以这样理解 数据库是“按照数据结构来组织、存储和管理数据的仓库”。是一个长期存储在计算机内的、有组织的、有共享的、统一管理的数据集合。(百度百科)
1.1.2 什么是数据库管理系统(DBMS)
数据库管理系统主要用来操作和管理数据库的软件, 也可以称为数据库软件。它对数据库进行统一的管理和控制,以保证数据库的安全性和完整性。
比如:MySQL,Oracle,SQL Server、MongoDB等。
数据库可以保存在硬设备上的文件,但也可以不是,究竟数据库是不是文件还是别的什么东西不重要,因为你并不直接访问数据库,而是使用DBMS去访问数据库。
1.1.3 什么是数据库系统(DataBase System)
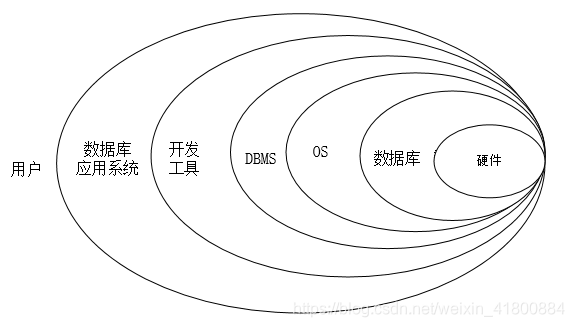
数据库系统是指在计算机系统中引入数据库后的系统,由数据库、数据库管理员及其管理软件组成的系统, 包含了数据库、数据库管理系统、应用系统、数据库管理员,数据库开发工具。
1.1.4 什么是概念模型
概念模型就是在了解用户的需求,用户的业务领域工作情况以后,经过分析和总结,提炼出来的用以描述用户业务需求的一些概念的东西。 如销售业务中的“客户”和“定单”,还有就是“商品”,“业务员”。
实体(Entity)是客观存在并可以互相区分的事物,从具体的人,物,事件到抽象的状态与概念都可以用实体抽象地表示。比如一个人,一个学生。
属性(Attribute) 是实体所具有的某些特性。由属性组成实体,通过属性对实体进行描述。比如一个人的名字。
码(Key):如果有一个属性或者属性集能够唯一地标识每一个实体,则称该属性或属性集为该实体的码。比如一个人的身份证,学生的学号。
1.1.5 什么是数据模型
数据模型是对客观事物及联系的数据描述,是概念模型的数据化,即数据模型提供表示和组织数据的方法。
三种数据模型:层次模型,网状模型,关系模型。(了解,详细看《数据库系统概论》)
- 层次模型:用树形结构来表示各类实体以及实体间的联系,每一个结点表示一个记录,结点之间的连接表示记录间的关系,这种联系只能是父子联系。
- 网状模型:==是一种比层次模型更具普遍性的结构,它允许多个结点没有双亲结点,也允许一个结点有多个双亲结点,因此网状模型可以方便地表示各种类型的联系。==一般来说,层次模型是网状模型的特殊形式,网状模型是层次模型的一般形式。
1.1.6 关系模型(重要)
网状和层次模型很好解决了数据集中和共享问题,但是在数据的独立性和抽象级别上仍有很大缺陷,用户在对这两种数据模型进行存取时仍需要明确数据的存储结构,指出存取路径,然后就出现了关系模型。
关系模式是用二维表格结构表示实体及实体间的联系的数据模型。 标准数据查询语言SQL就是一种基于关系数据库的语言,这种语言执行对关系数据库中数据的检索和操作。像MySQL,Oracle等属于关系型数据库。
1.1.7 非关系模型(参考百度百科)(NoSQL No Only SQL)
指的是分布式的、非关系型的、不保证遵循ACID原则的数据存储系统。
NoSQL数据库适合追求速度和可扩展性、业务多变的应用场景。 对于非结构化数据的处理更合适,如文章、评论,这些数据如全文搜索、机器学习通常只用于模糊处理,并不需要像结构化数据一样,进行精确查询,而且这类数据的数据规模往往是海量的,数据规模的增长往往也是不可能预期的,而NoSQL数据库的扩展能力几乎也是无限的,所以NoSQL数据库可以很好的满足这一类数据的存储。
目前NoSQL数据库仍然没有一个统一的标准,它现在有四种大的分类:
(1)键值对存储(key-value):代表软件Redis,它的优点能够进行数据的快速查询,而缺点是需要存储数据之间的关系。
(2)列存储:代表软件Hbase,它的优点是对数据能快速查询,数据存储的扩展性强。而缺点是数据库的功能有局限性。
(3)文档数据库存储:代表软件MongoDB,它的优点是对数据结构要求不特别的严格。而缺点是查询性的性能不好,同时缺少一种统一查询语言。
(4)图形数据库存储:代表软件InfoGrid,它的优点可以方便的利用图结构相关算法进行计算。而缺点是要想得到结果必须进行整个图的计算,而且遇到不适合的数据模型时,图形数据库很难使用。
ACID原则:指数据库事务正确执行的四个基本要素的缩写。包含:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。一个支持事务(Transaction)的数据库,必须要具有这四种特性,否则在事务过程(Transaction processing)当中无法保证数据的正确性,交易过程极可能达不到交易方的要求。
1.1.8 关系模型与非关系模型
参考
非关系型数据库的优势:
- 性能
NOSQL是基于键值对的,可以想象成表中的主键和值的对应关系,而且不需要经过SQL层的解析,所以性能非常高。 - 可扩展性
同样也是因为基于键值对,数据之间没有耦合性,所以非常容易水平扩展。
关系型数据库的优势:
- 复杂查询
可以用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询。 - 事务支持
使得对于安全性能很高的数据访问要求得以实现。
1.1.9 表(Table)
把数据库看成文件柜,那么如果在存放资料时,并不是将它们随便扔进文件柜的某个抽屉,而是在某个抽屉贴上特定的标签,然后把资料存放进该特定的抽屉中。
该抽屉在数据库在领域中被称为表。表是一种结构化的文件,可用来存储某种特定类型的数据。比如保存顾客清单,产品目录等。下面就是一张表。
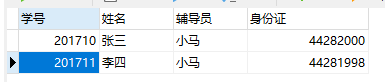
表具有一些特性,这些特性定义了数据在表中如何存储,如可以存储什么样的数据(类型),数据如何分解(看下面列中的解释),各部分信息如何命名等。描述表的这组信息就是所谓的模式(Schema),模式可以用来描述数据库中特定的表以及整个数据库(和其中表的关系),详细请看。
1.1.10 列(Column)和数据类型
列是表中的一个字段,是某一个事物的一个特征。 所有的表都是由一个或多个列组成的。列也可以称为属性。
解释一下数据分解:正确的把数据分解为多个列极为重要,例如城市,省,邮政编码应该总是独立的列。通过将它分解开,才有可能利用特定的列对数据进行排序和过滤。如果城市和省组合在一个列中,则如果按照省进行排序或者过滤很困难。
数据类型是指所容许的数据的类型。

1.1.11 行(Row)
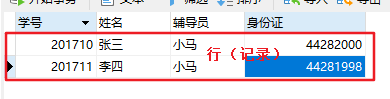
行指的是表中的一个记录(元组),事物特征的组合,可以描述一个具体的事物。 例如学号是什么,名字是什么等这些。提到行时称其为数据库记录,这两个术语可以互相代替。但从技术上说,行才是正确的术语。
表就是记录的组合,表示同一类事物的组合。
目前先从关系型数据库学起
1.2 关系键
1.2.1 主键(Primary Key)
表中每一行都应该有可以唯一标识自己的一列(或一组列),这就是主键。 每个表虽然不总是都需要主键,但是大多数数据库设计人员都应保证他们创建的每个表至少具有一个主键。
表中的任何列都可以作为主键,只要满足以下条件:
-
任意两行都不具有相同的主键值。
-
每个行都必须具有一个主键值(主键列不允许NULL值) 。
主键的最好习惯:除了MySQL强制实施的规则外,应该坚持的几个普遍认可的最好习惯:
- 不更新主键列中的值;
- 不重用主键列的值;
- 不在主键列中使用可能会更改的值。
1.2.2 超键(Super Key)
在关系中能唯一标识元组的属性集称为超键。 比如学生表可能有学号和身份证的字段,那么它们两的组合或者含有它们两者之一的都是超键。比如(学号,姓名),(学号,身份证)等。
1.2.3 候选键
候选键是不含有多余属性的超键,属性最小的超键。 比如(学号)、(身份证)。
1.2.4 外键
如果一张表中的某个字段是在另一张表作为主键,那么该字段就是外键。 比如辅导员这个字段,就有可能有一张辅导员信息表来记录辅导员的信息。
